<< content
Chapter 6
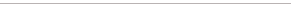
Static data and linear data in movie sequences
In pathways (or movie sequences), there are static data
and linear data. Static data is considered the “existence” of an object and
linear data is considered the linear steps of an object, event or action.
One example of static data is a TV guide. Each week, my local newspaper
would have 1 week worth of TV schedules. The TV guide is static data
because shows on the TV guide are fixed for one week. Another example of
static data is a person’s medical form. The form depicts background
information about the person such as name, phone number, age, gender,
occupation and so forth.
These static data can change over time. For example,
the person’s medical form can change some of its slots, such as the age of
the person or his/her occupation. A TV guide, on the other hand, will
change every week. The TV shows for last week is different from the TV
shows this week. The movie sequence record static data by the existence of
that object. If the robot was looking at a form for 10 minutes, the form is
existing in the 10 minute movie.
In the case of a 4 page form, the robot is recording
the 4 pages in memory in terms of the 3-d representation of the form. The
robot will record, in his memory that he has flipped through 4 sequential
pages of a form. Sometimes, the robot will flip the forms backwards or skip
pages. The important idea is that the robot can store each page in their
respective 3-d location in memory regardless of how the robot flips through
the pages of the form. In other cases, the robot can be confused and forget
which page goes first, second or last because of the chaotic way the pages
are looked at.
Another factor is the linear way text is read from the
pages in 3-d space. The recognition of text is stored in the page, where it
was read (in 3-d space). Reading text on a page requires zooming in on the
page. If the robot looks at the full page, the static data won’t record any
text, just garbles of lines and simple color. Only when the robot zooms in
and id the text will the text be stored in
memory.
Linear data, on the other hand, records sequence of
events. The ABC block problem is a good example because it requires linear
steps in order to solve. Solving a math equation, like addition or
subtraction also include linear steps.
FIG. 22 depicts a diagram that shows how static data
and linear data are stored. The static data records the robot looking at
the existence of an object. The data in memory loops itself and simply make
an object’s powerpoints stronger. The object
could be a medical form and the robot is storing the medical form in memory
(as the texts are read in). The first couple of frames might record the top
half of the medical form and the next couple of frames might record the
bottom half of the form. Once the entire form is read, the form is stored
in memory; and the robot’s brain will make the existing data on the form
stronger if it encounters it in the future. Data on the form will forget as
time passes. If the robot reads the form again, the slots in the form will
be stronger in memory.
The linear data will record how objects animate
themselves. When a block is moved from one location and another block is
moved to take its place, then the movie sequences recorded the animation of
replacing a block.
FIG. 22
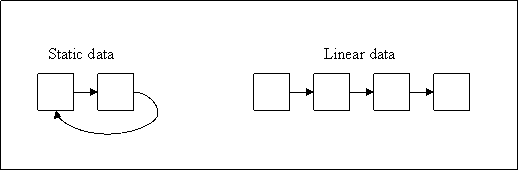
Pathways in memory use both static data and linear data
to store information. If you read a science book, you will notice a lot of
pictures and diagrams illustrating how procedures or systems work. Some of
the diagrams depict a fixed machine and the text in the book describes what
each component of the machine does and how they work. Facts about certain
areas of the machine are described.
Linear data and static data are interconnected in terms
of learning knowledge. They give the robot a wide range of “capabilities”
to store data. For example, if the robot was reading a science book on how
a neural network works, a diagram of a neural network might be large and the
diagram might have many small elemental parts. The
robot see the diagram in fragmented areas and moves its eyes to focus
on elemental parts or the overall diagram. This behavior will ultimately
form a static data on the full diagram in memory, as well as, the focus and
movement of seeing the elemental parts.
This is important because when the robot activates the
diagram in the future to answer questions, the mind can move freely in any
direction in the diagram and focus on any elemental part of the diagram.
There are primarily three elemental parts to a neural network: input layer,
hidden layer, and output layer. If the question asked was to describe what
the input layer is, then the robot has to extract a diagram of a neural
network, focus on the input layer, and activate facts related to the input
layer. Using this knowledge it can answer the question. Another method is
to extract the diagram of a neural network, focus on the input layer, use an
intelligent pathway from memory to analyze the properties of the input
layer, and output an answer.
Even in a medical form, the robot has to focus on small
areas of the form like the slots and x-ray pictures and so forth. If the
robot wanted to retrieve the patient’s name, he has to activate the medical
form in his brain and focus on the name slot. If he wanted the occupation
of the patient, he has to focus on the occupation slot.
In most cases, when the robot reads a text form, the
recognition of the words will activate visual images (or other 5 sense data)
and that visual image will be stored next to the word that activated it.
For example, when the robot reads a patient’s medical form and focus on the
patient’s occupation, the image of the occupation will activate. If the
occupation was a garbage worker, an image of a garbage truck will be stored
near the occupation slot. When the robot recalls the medical form in the
future, and when he focuses on the occupation slot, he will see a garbage
truck and he will know that the patient’s occupation is a garbage worker.
By the way, when the garbage truck image activates in the robot’s mind, his
brain selects an intelligent pathway to interpret the image. The
intelligent pathway will analyze the image and assume the patient’s
occupation.
Either the recalled memory of the medical form contains
sound data (the sound of the word/s) or it contains a visual picture.
Rarely, does the medical form (or any text form) contain visual text.
Learning, configuring and storing data
To better understand how pathways learn knowledge, I
decided to use five examples: 1. reading
novels. 2. reading comic books. 3.
reading history books. 4.
reading science books. 5. learning
science lessons from teachers. These five examples show how the robot can
learn knowledge in books and to store this knowledge in an organized way in
memory.
1. Reading novels
When reading any book, the robot fabricates a make
believe movie in memory based on the text read. This fabricated movie is
generated to give a visual idea of what the story is about. This fabricated
movie is based on activation of the meaning to sequential text. The robot
creates a make believe movie (based on the 5 senses) to visually see what
the story is about.
This fabricated movie is very complex because it
contains interconnected objects, events and actions. Relational links
between objects are established. Let’s use a popular book like the lion the
witch and the wardrobe. The objects involved are: the characters, scenes
and the narrator. During the reading of the book, every word read by the
robot will activate a primitive movie that explains the happenings in the
story.
The robot’s brain stores data in a 3-d manner. The
visual environment from the story is primarily where the events in the story
will be stored in memory. For example, at the beginning of the book, the 4
children are located in the professor’s house. The robot will visualize
what the house look like. Imagine that the first few pages describe the
children in the kitchen talking and eating. The robot will fabricate a
visual environment of a kitchen and what the characters should look like in
the story. In the next couple of pages, the children plays hide and seek in
the top floors of the house (the kitchen is located in the bottom floor).
The robot will visualize the structure of the house and designate the
kitchen is in the bottom floor and the rooms are in the top floors. A
recording of a timeline will also be presented, whereby the children was in
the kitchen and then they went to the rooms.
The words in the text describe how the characters look
and what their personalities are. This information gives the robot a
composite of each character. Things that are not in the book will be
assumed by the robot. For example, if the detailed descriptions of the
characters are not given and only a general idea, the robot can assume what
the detailed description might be. If the author simply wrote that Lucy is
a little 7 year old girl, the robot will add things like blonde hair (the
story takes place in England), wears a pink dress and have one missing
tooth.
If Edmund was described as a grouchy stupid teenager,
the robot can make up a visual image of what Edmund might look like based on
personal past experiences. Teenagers living in the 1800’s wear mandatory
school clothing; and that might be the image the robot fabricated for
Edmund.
FIG. 23 is a diagram depicting the scene of events in
the story. In the fabricated movie of the book, the scenes are outlined and
their locations in 3-d space are just estimates. If you read books or watch
movies, the authors do a very good job in setting boundaries of scenes.
After reading the book, I was able to map out the sequential scenes in the
book. Sometimes, the author revisits a scene. For example, the lion was
killed on the stone hedge. At the end of the book, stone hedge was a place
to celebrate their victory. In another example, the story begins in the
house and ends in the house. Thus, repeated scenes in the book will be
noted by the robot. He is able to tell what scenes were encountered, even
if they are repeated, in a linear way.
The above example shows that the sequences of events in
the story are stored in a 3-d environment. What about the characters and
their actions? It all goes back to my original patent applications and
books. The robot tags each character in the sequential movie with
relational links. All actions and knowledge about a character is stored as
one object floater (or a network of data). If the robot needs information
about lucy, he can
access the lucy floater. In this floater, all
information that the robot has encountered on
lucy will be there.
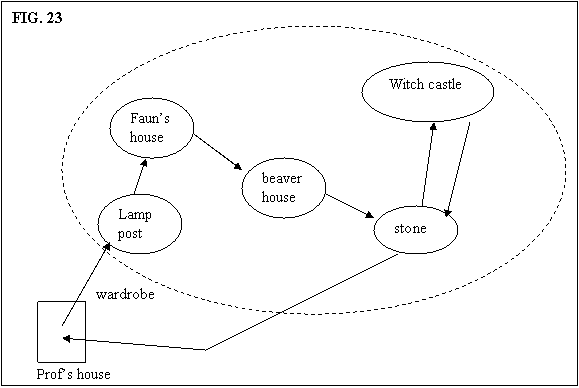
FIG. 24 is an example of how the
lucy floater is created. Lucy is
encountered 3 times in different scenes in the story. In the first scene,
located in the prof’s home, the author describes what
lucy looks like and her personality. In
the second scene, located in the faun’s home, the author explains to the
reader what lucy
did. Finally, in the third scene, located in stone hedge, the author talks
about lucy’s past.
All three scenes encountered gives new information about
lucy. Since the
fabricated movie is stored in a 3-d environment, this would mean that the
object lucy is stored
in multiple places (it doesn’t have a fixed area to store
lucy). However, even though
lucy is stored in
multiple places, there are reference pointers that id all
lucy objects in the fabricated movie. When the
robot wants to access information about
lucy, he can locate the
masternode (the lucy
object with the strongest powerpoints) and this
masternode has reference pointers to all other
copies of lucy in memory. The information about
lucy are considered
the element objects and all element objects gathered will compete with one
another to activate in the robot’s mind from the target object
lucy. This method shows that all data related
to one object can be accessed in a global fashion.
FIG. 24
For fixed objects like environments, it is easy to
assess that environment’s facts/knowledge. However, moving objects like
people and animate objects that move around a lot,
need to access their information in a global fashion.
Why does the fabricated movie store things in a 3-d
environment? Well, because the robot experience real life in a 3-d
environment. It learned that the real world is 3-d and it applied that
knowledge to a story in the book. In the first scene about the kitchen, the
robot learned, from past experiences, that he has to move from the kitchen
and climb the stairs to get to the second floor’s rooms. The characters in
the story are moving from the kitchen to the second floor. Thus, the 3-d
environment learned in the real world is being applied to the 3-d
environment in the story.
3-d encapsulate 2-d and 1-d.
The robot can also understand 2-d data like a song. The robot can also
understand 1-d data like a picture. If the character in the story picks up
a picture and talks about the picture, the robot knows that the picture is a
1-d object. It doesn’t move and the humans in the picture are not
animated.
2. Reading comic books
It is slightly different when reading a novel compared
to a comic book. In fact, it’s a totally different experience. In a comic
book, there are pictures and captions to read. Rules have to be followed in
order to read a comic book (I discussed these rules in previous books).
Captions come from characters in the book as well as the narrator, who is
telling the story.
There is no need to fabricate a “full” movie of the
story in the comic book because the pictures of events are given on the
pages. In each page, panels are used to show snapshots of scenes. The
panels are arranged from the top-left to the bottom-right. There are some
exceptions, such as double page spreads or side pages. The pages in a comic
book are static data – they don’t move because they are still pictures.
Intelligent pathways from the robot will guide the
reading of the comic book. These intelligent pathways will also determine
what captions belong to what characters. Sometimes, logic is needed in
order to understand who is speaking. For the most part, captions have
arrows that point to the character speaking the words. All the robot has to
do is look at the arrow and assign the caption to a character.
There are two types of pathways that are being
generated simultaneously by the conscious of the robot. The current pathway
is the experience of reading the comic book. The pages of a comic book are
static data and the robot focuses on panels on a page – linking these panels
in a sequential manner. One page of the comic book is stored in memory as
one static data. The sequence of panels are referencing where each panel
was encountered in the full page. By the time the robot see all the panels
in page3, memory will have page3 stored as a static data. The robot’s
long-term memory will store the linear panels encountered in page3.
While this is happening, the robot identifies objects
in the comic book pages. Characters, events, actions and narrators are
recognized. Each object will be tagged with their learned groups. For
example, if the robot was reading an X-men comic book, and he recognizes
wolverine, then the learned word wolverine will be tagged to the character.
If the robot recognizes an action, such as wolverine
jumping, then the event will be tagged with the learned words: “wolverine
jumping”. Thus, the robot’s conscious provides identification of
objects, events and actions.
In addition to identifications of objects, events and
actions, the conscious also provide facts and information on these objects.
Logical facts about objects will also be stored in the current pathway.
The current pathway and its conscious thoughts are one
type of pathway. The next type of pathway is the fabricated movie. When a
caption is read, the meaning of the words establishes relational links with
the characters in the story. The words might give information about
characters or provide a past event. Some of these words have nothing to do
with the pictures on the comic book. For example, one caption is telling
the reader what a character in the comic book is thinking of. A character5
might be sad in one panel and his thoughts are: he lost a good friend in
the past. The fabricated movie created a movie that shows character5
watching a friend die or character5 looking at the grave of a friend. This
fabricated movie provides visual meaning to the captions.
These fabricated movies will be stored right next to
the caption that the robot encountered. This fabricated movie serves as
separate data from the current pathway. However, this data will co-exist
with the current pathway in the same memory area. FIG. 25 is a diagram
showing a comic book page. For simplicity purposes, only three panels will
be illustrated.
FIG. 25

FIG. 26
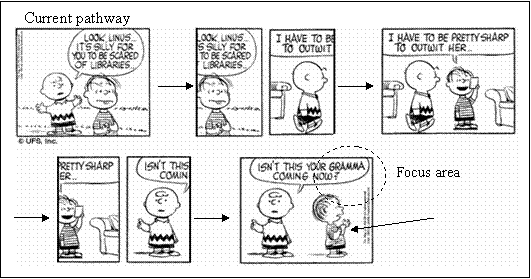
In FIG. 26, the current pathway records the robot’s
reading of the comic book. In each frame, the robot has a focused area and
a peripheral area (the arrow is pointing at the peripheral area). The robot
will be looking at the images in the panels and reading the captions. The
robot learned that it has to look at the first panel, finish looking at the
images and reading the captions, then go to the second panel, finish looking
at the images and reading the captions, finally go to the third panel,
finish looking at the images and reading the captions.
Although in the current pathway, the robot is looking
at different sections of the comic book, memory will only be storing a
static data on the comic book. The static data will look like FIG. 27. As
the robot reads the comic book linearly, the static data is formed in
memory. The diagram also shows that a fabricated movie is stored right next
to the captions. These fabricated movies will have relations to the robot’s
current pathway and its conscious thoughts. This means that objects in the
comic book will have multiple relations to each other based on the current
pathway, the conscious thoughts, and the fabricated movie.
FIG. 27

With all this information stored in memory (the current
pathway, the conscious thoughts and the fabricated movies), the robot has a
clear understanding of the comic book. If someone asks the robot a question
about what happened in the comic book, the robot will be able to recall the
comic book and give specific information.
Another interesting thing about the fabricated movies
is that it can take a still picture from the comic book and create a short
animation of that picture. For example, in the second panel, Charlie brown
is walking. The conscious of the robot can fabricate a short animation of
Charlie brown walking based on one still picture. This gives the robot a
more detailed recollection of what is happening.
Imagine if there were two panels, in the first panel
Charlie brown is standing on top of a table and the second panel shows
Charlie brown on the floor crying in pain. The robot can fabricate a short
animation of Charlie brown standing on the table, falling, and landing on
the ground. The frames in this fabricated movie will be very close to the
images in the panels. For example, Charlie brown will look like Charlie
brown and not another character. The table will look like that table in the
comic book and not a table in real life.
This is very important because the robot’s conscious is
trying to fill in any missing data from the comic book. Let’s say there
were two sequential panels. In the first panel there is a character1’s face
and he is talking. On the second panel is a character2’s face and he is
talking. The panels do not say that character1 is facing character2 and
vice versa. Because of intelligence and because we fabricate that a
character1 is facing character2, we are able to “know” that they are facing
each other in a 3-d manner. The fabricated movie of these two panels will
include a simple illustration of character1 and character2 in a 3-d
environment that show them facing each other. This fabricated movie is just
a basic illustration (comprising of lines and arrows and cartoon
animation). Maybe, when the robot looks at the first panel, the robot will
draw a line with an arrow outward towards something. The text in the
captions will say who the arrow will point to (mainly character2). Maybe,
the robot’s conscious will show a 3-d grid with simple stick figures to
represent character1 and character2. It really depends on the lessons
learned in school.
3. Reading history books
History books contain facts/knowledge about different
subject matters. How does the robot’s brain store this knowledge in
memory? Sentences can encapsulate many form of information. Sentences can
describe an object, explain a definition, answer a question, give facts
about an object, predict the future, convey a message from an object,
explain personal views, convey humor, and so forth.
In some respects different type of sentences should
have different ways of storing data. For example, defining the definition
of a word should be different from explaining a visual environment (in terms
of storage of data).
FIG. 28 shows how a definition of a word is stored in
memory compared to explaining a visual environment. When storing definition
of a word, the word is the target object and the meaning is the element
object. The robot’s brain should store the word close to its meaning
because they are equal. On the other hand, if sentences are used to
describe a 3-d environment, the robot’s brain will generate the visual
aspects of the sentences and store them in a 3-d manner. These two examples
show that different sentences store data differently. It is up to the robot
to average out lessons learned in school and to find the patterns between
storing data and the different types of sentence structures.
FIG. 28

If you look at medical books, they will show you
visually the different parts of a human being. These parts are encapsulated
in a human object. The head, or hand, or leg is a part of a human being.
When facts are given about an object, these facts will be stored in the
visual representation of that object. For example, if the object was a
heart, and the robot was learning about facts related to the heart, that
knowledge will be stored in the visual heart. The heart is stored in the
human being. Knowledge about the eyes will be stored in the visual eye
area, knowledge about the hand will be stored in
the visual hand area and so forth. This is a very powerful way of
organizing knowledge. Visually, the human body is very complex, but the
brain is able to learn where certain body parts are located in the human
body and store related information in their respective visual area. The
more knowledge learned about a body part, the more organized the knowledge
for that body part is.
There are some facts that store the interaction of two
or more body parts. These types of facts can be stored in any object
involved (usually the strongest object). But the area that the fact is
stored in should have reference pointers to all objects involved. This is
how a minor object involved in the fact can activate the minor object.
Facts that relate to sequential steps and processes are
also stored in arbitrary areas. The self-organization of data can
migrate knowledge from one area to another.
Animate objects in memory have no fixed positions (like human beings).
Sometimes, there are multiple copies of a human being in the robot’s brain.
In my patent applications I show how sequential steps self-organize, such as
the ABC block problem. Also, I show how a human being is stored in memory.
These non-fixed objects are stored in different areas in memory and there
are multiple copies. Self-organization will minimize the storage of
repeated copies.
Storing knowledge by learning how to store knowledge
The robot learns knowledge from school lessons and
these knowledge are already stored in an organize manner. If you look at a
form, for example, they list the slots of a person in an organized manner.
The name is always the first thing you see, followed by other secondary
slots, such as age, phone number, occupation, gender, race and so forth.
The robot takes all the forms that it encounters during its lifetime and
creates a template form in memory that will store slots and their respective
values.
Each person that the robot encounters already has a
template form stored somewhere in memory. When information about the person
is given, such as their name, the robot takes the name and puts it in the
slot: “name”. In FIG. 29, data1 is known as the template form. This
template form has certain slots and the robot will fill in these slots based
on knowledge that it learns from the environment about the object Dave. If
the robot was introduced to dave
by someone and he said: “this is dave
palski”, the robot will take
dave palski and
store it in the template form under the slot: name. Facts learned such
as ”dave works as an
engineer” will be tagged to the template form and it should be located near
occupation.
FIG. 29
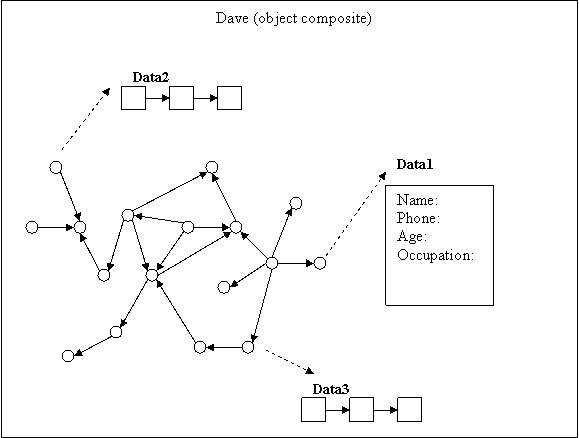
The process by which the fact about
dave is stored near
the occupation area is based on FIG. 30. The diagram shows that the robot
activated occupation as the identification of the fact. The robot’s
conscious id that the fact is stating
dave’s occupation. The fact will be
stored near occupation because of association. Both the fact belongs to
dave and the fact is
about occupation tags it to the occupation slot in the template form.
FIG. 30


Other lessons in school can also be learned to organize
data in memory. The transitive statement: A = B, B = C therefore A = C,
can be used to summarize events. The robot learns discrete math functions
and uses them to represent events in life. The robot actually analyzes a
situation first, using math functions to represent the situation and store
the logical data in memory.
The if-then statement is very powerful in terms of
recognizing something and taking action. This is very powerful in terms of
doing tasks like driving a car or playing videogames. If the street light
is green move forward, if the street light is red stop the car, and so
forth. Sequences of if-then statements can be used or simultaneous if-then
statements can be used.
These type of learned lessons (such as discrete math)
help to organize data from the environment that can be easily remembered.
These lessons also help to limit the different types of data organization
that are allowed in memory. Easier to understand data organizations or
limited data organizations will guide the search functions to find
information quicker.
Diagrams of different data structures can help in
organizing data. A hierarchical tree can explain the relationship between
parent and child. The first node represents the parent and the child node
represents children. Information regarding parent-child relationships can
use a hierarchical tree to store knowledge. All the knowledge of the parent
goes in the first node and all the knowledge of the child goes in the child
nodes. The knowledge in the tree will have relational links to objects in
the parent node or child node. Processes of relationships can also be
explained.
One of the reasons that teachers use a hierarchical
tree diagram to explain relationships between a family
tree is because the facts are not static data, but are linear data.
Steps of how family members are related need to be explained in sequence
order. A diagram is drawn and a teacher has to explain what each family
member is and how they relate to other family members. Facts will be stored
near a family member. For example, the parent always has a mother and
father (there are some exceptions). The mother is always female and the
father is always male. Next, the teacher has to explain that the parents
created the child and the parents have a responsibility to take care of the
child. What are the functions of a parent, what does the parents have to do
for the child at certain ages, and so forth are stored near the hierarchical
tree (FIG. 31).
FIG. 31
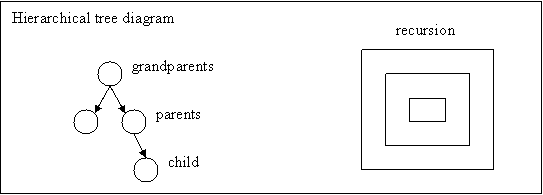
If the robot wants to know information about family
members, it will access the hierarchical tree diagram and search for facts
based on areas in the diagram. For example, if the robot wanted to search
for parent information, then it can search in the first node because that is
where the majority of knowledge related to parents are
located.
If the robot wanted to learn how the internet works,
diagrams on interconnected computers and a hub can be used (FIG. 32).
Explaining of the diagram will be the knowledge to describe how the internet
works (this subject matter will be revisited in the next chapter).
FIG. 32
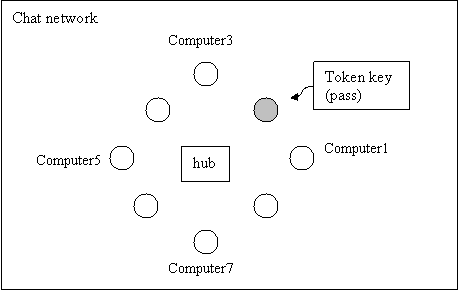
Complex things like knowing how the internet works,
knowing how data base system works, or knowing how object-oriented
programming works, will depend on visual diagrams in memory. These diagrams
are accompanied by many explanations, in terms of a fabricated movie, of how
complex things work. In some respects, using diagrams to represent complex
things will organize data more efficiently. For example, a family tree
diagram is very similar to an object oriented programming diagram.
Although, the two diagrams share a hierarchical tree as their commonality,
their knowledge is slightly different. The robot can also use family tree
knowledge to try to understand how object oriented programming works and
vice versa.
At the end of the day, the family tree diagram and the
object oriented programming diagram share a common trait and because of the
common trait they are brought closer together in memory. This method help
organize data in memory.
Configuration of data in memory
An object composite is just a network of data related
to one object. The above example about a template form,
depicts one example of how data is configured in an organized manner related
to one person. When people give important information about
dave (FIG. 29) like
his full name, address, phone number and occupation, these data are
identified and stored in slots in a template form.
This is how the robot “learns” to configure data from
the environment and to store them in memory in a meaningful and compatible
format. Other configurations of data might include diagrams learned to
store facts about a person. A hierarchical tree can store data on family
relationships and the behavior of family members.
In discrete math, there are diagrams that people draw
to show relationships and to store facts about objects. People learned from
teachers how to draw these diagrams on paper. These diagrams can be a form
configuration of data from the environment. It will create an organize
object composite, whereby information about that object is stored and
organized in memory according to learned diagrams.
For example, in some predicate calculus problems, the
robot has to translate sentences into a visual diagram. A circle might
represent an object and an arrow might represent a function. The writing
down of the action on the arrow indicates what function. The robot can
learn this behavior and generate its own type of data configuration, not
just based on sentences, but visual images or 5 sense data as well.
Another theory is that maybe a book can represent
information about a person. On the first page might be a form of the
person. In the later pages there might be pictures and facts about that
person. This template book is like a physical book, whereby the robot has
to flip through pages to get information. The physical book has a front
cover and a back cover so that it defines the boundary of this object
composite. Information in this template book might have relational links to
other template books.
To sum up this chapter, the brain learns diagrams from
textbooks and teachers and uses these visual diagrams to configure and store
data from our environment. No computer scientists are needed to write any
of the functions or classes. Things like database systems, image
processors, an operating system to manage
multiple tasks, and logic gathering are all done through lessons taught in
school.
The overall AI program illustrates an image processor
with 6 dissection functions (FIG. 1). To tell you the truth, the image
processor is not necessary. The robot learns how to delineate image layers
by examples in real life. If you observe teachers teaching students, the
teacher will point to an object and this pointing gesture is to guide the
students’ eyes to focus on the object. The human eye focuses on objects and
the object itself is clear, while all other surrounding objects are blurry.
This eye focus function automatically cut out a perfect image layer from the
environment.
The eye focus only works for 3-d objects in real life,
what about 2-d still pictures, how does the robot delineate these objects?
The robot encounters data in the real world, so it know what objects look
like in terms of 3-dimension. The robot learned what a dog looks like from
seeing a dog. When the robot see a dog in a 2-d still picture, the 3-d data
from a dog stored in memory will activate and it will give the 2-d still
pictures a 3-d shape. This 3-d shape delineates the image layer from the
2-d still picture.
8 Years ago I was watching Sesame Street to observe how
children learn information. I notice that one method that the
show delineate objects and to focus the eyes of
the child is to use a digital outliner. The scene is a chaotic jungle and
there are lots of trees and animals in the scene. The teacher would ask:
“where is the monkey”, and a few seconds later, the digital outliner will
outline the boundaries of the monkey.
This behavior is learned by the robot. He is able to
form a digital outliner to delineate the boundaries of any object in the
environment. However, the robot id image layers in an approximate manner
and not an exact manner. Identifying events and situations might be
difficult, but the robot will assume the approximate area or objects
involved in the situation.
If this behavior is learned by the robot, he will be
able to see in his mind an invisible digital outline of objects in the
environment. He is able to id what elemental parts belong to what objects
and determine their boundaries.
Learning data in history books
FIG. 33 is a diagram illustrating how the robot learns
knowledge in history books. Assuming that the robot reads the book
linearly, the pages are stored in memory like a physical book – page by
page. The page storage might be approximate and not entirely sequential.
The history book will have reference pointers to the robot’s long-term
memory, when each page has been read.

When the robot reads text from the pages, a fabricated
movie will activate and this fabricated movie serves the same purpose as
witnessing movie sequences from real life. However, the fabricated movie is
fuzzy and is constructed by cutting, pasting and merging 5 sense data
together based on the text read. The conscious thoughts will activate to
identify objects in the pages and to give facts or provide logical
analysis. In addition to the fabricated movie and the conscious thoughts
are the still pictures, text configurations and diagrams from the history
book. Some sentences are describing the pictures on the page and the
robot’s brain has to establish relational links between the text and
picture.
The conscious thoughts are vital to the remembering and
the storing of data. The robot will use logic to id paragraphs, to
delineate chapter boundaries, to summarize paragraphs, to interpret
alternative meaning to complex sentences, identify important facts and so
forth. These thoughts really help to organize the data and prepare it to be
stored in memory.
All the data from the physical 3-d history book and the
fabricated movie are stored in fragmented places in memory. There are two
types of areas that the data will be stored in: the optimal pathway and
masternodes of objects in the current pathway.
The robot’s brain jumps from one area in memory to the next in order to
store the current pathway. Thus, the physical 3-d history book is stored in
fragmented areas in memory. It will attempt to store the current pathway in
a linear fashion. The only thing that binds the history book together is
the long-term memory. Next, other data like fabricated movie, conscious
thoughts and still pictures are also stored in their
masternodes (the area each data is strongest in). For example, if
there exist a dog picture in the history book,
the dog picture will be stored in the optimal pathway and it will be
retrained in the strongest area where a similar looking dog image is
stored. Retraining data is based on storing a copy of the original with
less data. Or, if the copy already pre-exist in the strongest area (the
masternode) the pre-existing data will be
strengthened.
Over time, the robot’s brain forget
information. Let’s say that 10 years after reading the history book the
robot forget ever reading the history book. That doesn’t mean the
information from the history book is completely gone from memory. You still
have data stored in the masternodes. This means
that the majority of content from the history book still exist even though
most of the physical 3-d book stored in memory is forgotten.
The physical 3-d history book is very important in some
cases. If the robot was asked this question: “what chapter describes world
war II”, the robot has to activate a memory of the physical history book,
locate world war II data, and logically output the probable chapter. In
order to do this, the robot’s brain has to use an intelligent pathway that
analyzes the history book. This intelligent pathway will locate the
world war II chapter, flip through chapters
before it and flip through chapters after it and determine where the chapter
is located. In the robot’s mind the physical book in terms of its 3-d shape
and size are stored in memory. If the robot determines that the
world war II chapter is located in the middle of
the book and the book has 20 chapters, then it can assume that the world war
II chapter is chapter 10. If the robot determines that the
world war II chapter is located in the beginning
of the book, he will say chapter 3 or 4.
The conscious thoughts activate what chapter while
you’re reading the chapter. This will make it easier to organize the
knowledge.
Other questions asked might be: write down a summary
of all chapters in the book or explain what caused world
war II? The first question uses both the physical 3-d history book
and content in the masternodes. On the other
hand, the second question uses only the masternode
information. The robot doesn’t need to know what chapter
world war II is located, he just needs to know
information about world war II.
Data in memory have multiple copies scattered
throughout the robot’s brain. The masternode is
the strongest copy of that data and it has reference pointers to other
weaker copies in memory. The primary storage area for a data is stored in
the optimal pathway, which may or may not be the
masternode. This type of learning is required because all data in
memory are global and interconnected. Regardless of where the current
pathway is stored in memory, each object in the current pathway must locate
its respective masternode to be retrained.
<< content
next chapter >>